

Если бы возможно было одним нажатием кнопки отключить все алгоритмы, «сломался» бы сам интернет, поскольку распределением нагрузки на узлы сетей уже давно занимается ИИ. Эндрю Ын, сооснователь и бывший руководитель Google Brain, как-то сравнил ИИ с электричеством. Он сказал, что скоро не останется такой сферы, на которую не повлиял бы искусственный интеллект. Но готовы ли алгоритмы заниматься творчеством?
Творец или инструмент
Принято считать, что все существующие алгоритмы относятся к категории так называемых «слабых» ИИ. Они нацелены на решение либо какой-то одной задачи, либо пула задач, относящихся к одной области. Что такое «сильный» ИИ, мы пока не знаем. Можно сказать, что это алгоритм, обладающий самосознанием и разумом, пусть даже и не похожим на человеческий. Скорее всего, «сильный» ИИ будет способен на творчество. Но как обстоит дело с современными алгоритмами? Изучением и развитием методов создания ИИ занимается машинное обучение (ML, Machine Learning).
Специалисты в этой области не дают машине пошаговую инструкцию, как достичь определённого результата, а учат её самостоятельно приходить к этому результату при минимальном вмешательстве человека. Чтобы обычная программа находила на фотографиях котиков, программисту потребовалось бы разложить понятие «котик» на тысячи характеристик. Хорошему ML-алгоритму достаточно показать тысячу фотографий, на которых фигура котика обведена и подписана.
С одной стороны, такой способ обучения сильно упрощает жизнь. С другой, для обучения ИИ требуется найти эту тысячу фотографий и разметить на ней нужные объекты. В интернете уже есть несколько крупных баз с данными, на которых можно тренировать алгоритмы, есть и множество мелких, более специфичных. Причём не только с изображениями, но и с текстами, анимацией, аудиозаписями. И тут важно помнить, что данные для обучения ИИ собирает и размечает всё тот же человек. От человека зависит, насколько они разнообразны и точны. В английском языке это иллюстрирует идиома GIGO — garbage in, garbage out (переводится как «мусор на входе — мусор на выходе»). Грубо говоря, не стоит ожидать шедеврального романа от алгоритма, который учился на бульварном чтиве.
 Изображение, которое сгенерировала нейросеть после тренировки на картинах в стиле модернизма
Изображение, которое сгенерировала нейросеть после тренировки на картинах в стиле модернизма
Широко известен тот факт, что распознавание лиц в алгоритмах компьютерного зрения (тех, что анализируют изображения) для представителей неевропеоидных рас работает на порядок хуже, чем для белых людей. Это связано именно с неравной репрезентацией всех рас в тренировочных данных. В 2015 году даже случился скандал: распознающий алгоритм в Google Photos не узнал в двух афроамериканцах людей и пометил их как горилл. Для таких ошибок есть название, AI bias — предвзятость искусственного интеллекта, приводящая к искажениям в результатах. Мы можем, сами того не замечая, научить алгоритмы расизму, сексизму и прочим нехорошим вещам. Это может найти отражение и в сфере искусства.
Ещё одна проблема с ИИ состоит в том, что мы пока плохо понимаем, каким образом он приходит к тому или иному результату. У неё тоже есть название — проблема интерпретируемости, и сейчас учёные понемногу продвигаются к её решению. Ситуация осложняется тем, что параметров, которыми оперирует алгоритм, безумно много, а работа кое-каких моделей — из тех, что уже выполняют важные задачи, — вообще не поддаётся объяснению, поскольку их архитектура изначально не учитывала необходимость интерпретации результатов. Что уж говорить о неспециалистах — простых людях, которые не могут залезть нейросети «в мозги» и посмотреть, на каком слое, из-за каких параметров она даёт сбой. По сути, сейчас искусственный интеллект — это чёрный ящик, и внутри него происходит загадочная магия. Если он нарисует абстракцию или сочинит мелодию, то не сможет объяснить, почему сделал её именно такой и какой за ней скрывается смысл.
В общем, не стоит торопиться и наделять искусственный интеллект теми качествами, которые ему не присущи. Однако это не мешает использовать его как хороший инструмент — тем более что интерес к результатам совместного с ИИ творчества понемногу повышается.
В 2018 году в Нью-Дели прошла выставка, полностью посвящённая предметам искусства, созданным с помощью искусственного интеллекта. В октябре того же года сгенерированная нейросетью картина была продана на аукционе Christie’s почти за полмиллиона долларов — рекордная сумма для такого типа изображений. Летом 2019 года международную художественную выставку «Искусственный интеллект и диалог культур» организовал Эрмитаж. Способны современные алгоритмы на творчество или нет, но они уже влияют на искусство. Насколько сильно — зависит от конкретной области.
Изобразительное искусство
«Портрет Эдмонда Белами» ушёл с молотка за 432,5 тысячи долларов, что в 45 раз больше его стартовой цены. Картину сгенерировала нейросеть, которую команда Obvious из Парижа натренировала на 15 тысячах портретов, написанных в период с XIV по XX век. Авторы проекта использовали уже существующую нейросеть с открытым исходным кодом — обычное дело в IT-среде. Это была GAN (Generative Adversarial Network, генеративно-состязательная нейросеть) — воплощение прорывной концепции, которая появилась всего шесть лет назад.
 Портрет Эдмонда Белами
Портрет Эдмонда Белами
В июне 2014 года исследователь из Google Brain (ныне работает в Apple) Ян Гудфеллоу с коллегами опубликовал статью Generative Adversarial Networks, в которой описал относительно простой, но гениальный принцип машинного обучения. Специалисты предложили стравить друг с другом две модели: генеративную и дискриминативную. Первая будет пытаться обмануть вторую, а вторая — распознать обман.
К примеру, генератору показывают много-много реалистичных пейзажей — такая база данных называется тренировочным набором — и поручают создать что-то похожее. Он генерирует фото, которое отправляется дискриминатору. Дискриминатор пытается определить, откуда оно пришло: из тренировочного набора или от генератора. Если изображение пришло от генератора, а дискриминатор подумал, что из набора, то генератор молодец — надурил соперника. Дискриминатор берёт это на заметку и в следующий раз постарается такое изображение не пропустить. Если же дискриминатор правильно распознал сгенерированное изображение, генератор в следующий раз постарается сделать такую фотографию, которая будет больше похожа на реальную.
Работу этих двух моделей часто сравнивают с противостоянием между фальшивомонетчиками и банками. Первые совершенствуются в копировании банкнот, а вторые — в выявлении подделок. Кстати, у команды Obvious есть целая серия сгенерированных портретов семейства Белами. Эта фамилия отсылает к фамилии автора концепции GAN: bel ami (фр.), как и good fellow (англ.), означает «хороший друг».
 Галерея нейросетевого искусства, раздел «Природа»
Галерея нейросетевого искусства, раздел «Природа»
Совсем недавно, в марте 2020 года, «Яндекс» создал Галерею нейросетевого искусства. Это сайт с виртуальной выставкой картин, сгенерированных StyleGAN2 и распределённых по разным секциям собственным алгоритмом компании. Всего там четыре секции: «Люди», «Природа», «Город» и «Настроение». Особенность выставки в том, что количество картин в ней ограничено (хотя ИИ способен создавать их тысячами), и каждый посетитель с момента открытия мог забрать одну из них себе, скачав оригинал изображения. Картины закончились за несколько часов — спрос был огромный.
Что-то несуществующее
В феврале 2019 года компания Nvidia выпустила нейросеть StyleGAN, а вместе с ней открыла сайт ThisPersonDoesNotExist.com. На этом сайте нейросеть в реальном времени создаёт фотографии лиц несуществующих людей, причём такого уровня реалистичности, что отличить их от фото настоящих людей очень сложно.
Во многих пабликах и каналах стали появляться тесты с призывом угадать, на каком изображении реальный человек, а какое сгенерировала нейросеть. Со временем люди научились их различать. Фокус в том, что на фотографиях нейросети фон всегда замыленный, а на периферии — в волосах, на плечах или на груди — можно заметить артефакты. Вскоре после открытия сайта стали появляться ресурсы-клоны, на которых StyleGAN создавала несуществующих кошек и лошадей, а также несуществующие химические соединения, вазы и сумочки.
 Этого человека не существует, его лицо создал StyleGAN2 — вторая версия алгоритма Nvidia.
Этого человека не существует, его лицо создал StyleGAN2 — вторая версия алгоритма Nvidia.
Литература
С текстами дело обстоит на порядок хуже, чем с изображениями. Если в художественной абстракции мы способны уловить красоту и некий смысл, то несвязный текст сбивает человека с толку. А связный алгоритмы генерировать пока не умеют — даже лучшие теряются после нескольких предложений. Впрочем, кое-каких успехов специалисты добились в области поэзии. Чёткая ритмика и приятное звучание фраз не компенсируют полностью отсутствие смысла, но могут доставить некоторое удовольствие. К примеру, у того же «Яндекса» с 2013 года работает сервис «Автопоэт» — это нейросеть, которая составляет стихотворения из поисковых запросов: «а было лето было лето / царицынский военкомат / измерить скорость интернета / чехол для асус мемо пад».
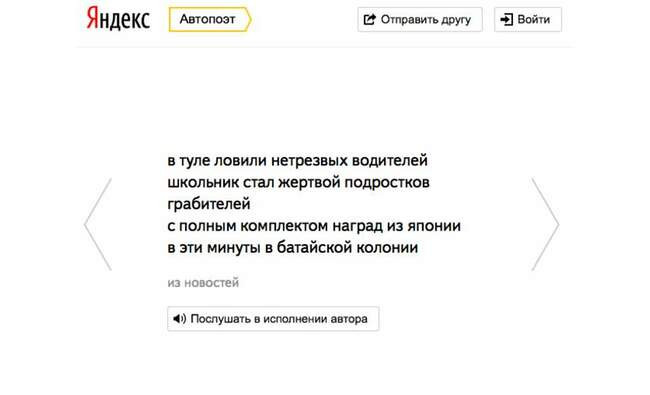
В 2016 году двое сотрудников компании натренировали нейросеть на песнях «Гражданской обороны», и алгоритм выдал тексты, которых хватило на целый альбом из тринадцати треков. Его назвали «404» и выпустили, указав исполнителем «Нейронную оборону». Даже обработали треки так, чтобы они на слух напоминали кассетные записи. К созданию музыки, правда, искусственный интеллект не привлекали.
В ожидании чудес,
Невозможных чудес
Я смотрю в темноту,
Но я не верю в прогресс.
«Заново мир» («Нейронная оборона», «Яндекс»)
В декабре 2017 года творческая команда из Botnik Studios изрядно повеселила интернет, а особенно поклонников серии про Гарри Поттера, главой из новой книги про Мальчика-который-выжил. Эту главу написал искусственный интеллект, и называется она «Красавчик», а сама книга — «Гарри Поттер и портрет того, что выглядело как большая куча пепла». Смысла в ней не то чтобы много: фразы алгоритм выдавал связные, однако они плохо стыковались друг с другом. Это объясняется принципом работы подобных моделей.
Они посмотрели на дверь, крича о том, насколько она была закрыта, и упрашивая её превратиться в небольшой шар.
— Пароль был «ГОВЯЖЬИ ЖЕНЩИНЫ», — завопила Гермиона.
Отрывок из несуществующей книги о Гарри Поттере от Botnik Studios
Алгоритмы обработки естественного языка (NLP, Natural Language Processing) более-менее хорошо представляют себе структуру языка и даже научились образовывать морфологически правильные словосочетания — это видно по тому, как продвинулись за последние годы автоматические переводчики. Ещё один большой шаг в сторону писательской карьеры алгоритмы сделали, когда научились предсказывать на основе контекста продолжение фразы, а на основе продолжения — следующий кусок текста. Примерно по тому же принципу работает автодополнение в современных цифровых клавиатурах. Но ИИ хорошо себя показывает на коротких дистанциях. Во время марафонов — когда нужно сочинить повествовательный абзац — он путается и несёт околесицу.
В феврале 2019 года компания OpenAI заявила, что создала универсальную модель генерации осмысленных текстов, но отказалась сразу публиковать полную версию, опасаясь, что её будут использовать в дурных целях — к примеру, для штамповки фейковых новостей. Модель GPT-2 действительно оказалась хороша, хотя не особо отличалась от предшественников и работала по принципу того же автодополнения. Её выделяло количество параметров — грубо говоря, настроек в узлах нейросети — и объём тренировочных данных. В полной версии модели 1,5 миллиарда параметров, тогда как в других алгоритмах используется 100– 300 миллионов. А обучали её на сорока гигабайтах текстовых данных. Натренированная GPT-2 способна выдавать краткое содержание нескольких абзацев, отвечать на вопросы, а главное — самостоятельно генерировать большие объёмы текста.
Два Кольца были возвращены в Ривенделл. Фродо и Сэм проснулись одни в комнате, и Фродо обнаружил на своей подушке записку. Он открыл её и прочитал: «Да пребудет с вами навечно сила Кольца и да не погаснет его свет».
Текст, сгенерированный GPT-2
Энтузиасты, так сказать, русифицировали эту модель — обучили на массиве текстов из русской литературы. Так появился развлекательный сервис «Порфирьевич» (вероятно, названный в честь главного героя Пелевинского «iPhuck 10» — Порфирия Петровича), а ещё чат-бот в «Телеграме» — NeuroPoetBot.
Пещера. Дымный чад факелов. Крылатые тени, мечущиеся под потолком. Косматая, позвякивающая кандалами толпа… У меня до сих пор сердце замирает при одном взгляде на это. А тут ещё полная луна в небе… Ощущение такое, что попал в авангард, когда писала эту статью про призраков. Здесь все такие примитивные.
Мария Семёнова («Волкодав») + нейросеть «Порфирьевич» (GPT-2)
В русскоязычном пространстве был ещё один творческий проект, к которому привлекли искусственный интеллект (и известного писателя). Летом 2018 года, перед выходом третьей части сериала «Гоголь», телеканал ТВ-3, «Яндекс» и Сергей Лукьяненко представили рассказ, написанный ИИ в стиле Николая Васильевича Гоголя. Рассказ назывался «Дурной договор».
«„Экая судьба!“ — подумал про себя Харитон и, пришедши к себе в комнату одеться и лёг в постель. Долго боролся он с бессонницею, наконец, пересилил её. Опять какой-то сон, какой-то пошлый, гадкой сон. Боже, умилосердись: хотя на минуту, хотя на одну минуту покажи её! Мою милую супругу, которую я ещё недавно держал в своих объятьях».
(Отрывок из «Дурного договора»)
За искусственный интеллект отвечал «Яндекс» — подобрал модель, натренировал на 30 тысячах произведений русской прозы и затем «дообучил» на творчестве классика. Сергей Лукьяненко придумал персонажей и подготовил основу для сюжета, которую ИИ сам заполнил псевдогоголевским текстом. Получилось не то чтобы хорошо, но, по словам самого Лукьяненко, имитировать стиль у алгоритмов уже получается: «Плохая новость — у нас порой выходят книги, написанные хуже, чем история, придуманная нейросетью „Яндекса“».
Музыка и кино
Генерация музыки нейросетям даётся, с одной стороны, проще: в ней нет такого жёсткого смыслового уровня, как в тексте, так что можно просто концентрироваться на благозвучии. С другой стороны, им приходится работать с очень увесистыми файлами. Однако на рынке уже есть приложения, в которых ИИ создаёт бесконечный музыкальный поток под разные настроения и в разных стилях.
Наиболее впечатляющих результатов добилась всё та же команда OpenAI. В начале мая 2020-го она опубликовала алгоритм, который способен генерировать музыку в разных жанрах, от блюза до тяжёлого металла, и даже с вокальными партиями — такого не было ещё ни у кого. Но и здесь не всё гладко. Создавать законченные композиции — с куплетами, припевами и повторяющимся основным мотивом — нейросеть всё же не умеет, к тому же работа алгоритма требует огромных вычислительных ресурсов: на генерацию трека длиной в минуту уходит девять часов. Кроме того, при синтезе вокала она использует образцы голосов реальных исполнителей, что поднимает вопрос о защите авторских прав.
Альбом блэк-металла, созданного ИИ DADABOTS
Некоторым экспериментаторам традиционных видов творчества не хватает, и они скрещивают между собой разные формы искусства, например живопись и музыку. Компания Awara IT решила проверить, сумеет ли нейросеть выявить связь между работами Василия Кандинского и композициями, которыми они были вдохновлены. Разработчики натренировали свой алгоритм на связках произведений: например, картина «Москва I» сопоставлялась с оперой Рихарда Вагнера «Лоэнгрин», «Импрессия III (концерт)» — с композициями Арнольда Шёнберга, — а затем предложили нейросети сгенерировать картину, соответствующую песне «На заре» группы «Альянс». Получился своеобразный перфоманс — автору песни, Олегу Парастаеву, он даже понравился, но к талантам искусственного интеллекта музыкант относится скептически: «Сам по себе искусственный интеллект не способен творить в полной мере — без участия человека искусством это не назовёшь».
В кино (и в принципе при работе с видео) нейросеть пока остаётся на вторых ролях, однако свои обязанности исполняет довольно хорошо. Сейчас алгоритмы умеют манипулировать фигурами на видео, менять лица людей, причём отлично справляются даже с мелкой мимикой. Есть такой ИИ, который меняет движения губ в ролике, и кажется, что человек говорит на другом языке. Всё это может однажды привести к тому, что зритель будет сам выбирать актёра, которого хочет видеть в определённой роли.
Впрочем, есть одна короткометражка, которую полностью срежиссировал искусственный интеллект. Его зовут Бенджамин, а фильм называется Zone Out. Главную роль в нём сыграл Томас Миддлдитч — звезда «Кремниевой долины». Бенджамин создал сценарий, выбрал из старых фильмов подходящие кадры, склеил их в сцены, подставил лица актёров в нужные места, озвучил их же голосами и написал саундтрек. Всё это он сделал сам за 48 часов. Получилась чёрно-белая нуарная фантастика об учёном, который пытается остановить распространение вируса, меняющего лица людей.
 В некоторых кадрах созданного ИИ фильма лица актёров всё же «подтекают»
В некоторых кадрах созданного ИИ фильма лица актёров всё же «подтекают»
Права алгоритма
До полноценного творчества искусственному интеллекту пока далеко, но вопрос с правами на его произведения встаёт уже сейчас. Полностью его не решили ещё нигде, власти многих стран пока за него даже серьёзно не брались, потому что внедрение ИИ в правовую область требует основательного подхода, долгой и кропотливой совместной работы законотворцев со специалистами в области машинного обучения. Однако кое-где нормы об охране результатов творчества нейросетей уже появились — к примеру, в Великобритании. Там авторские права принадлежат тому человеку, что создал условия для появления произведения. В разных ситуациях это может быть как разработчик нейросети, так и простой пользователь.
В России, как и в США, интеллектуальные права на предметы искусства, созданные ИИ, не охраняются. Этому мешает и структура закона об авторском праве, и в принципе то, как работают алгоритмы. Изображения, музыка и прочие произведения, сгенерированные нейросетями, подпадают под определение объекта права, который по закону следует защищать. Чаще всего они новы, оригинальны и уникальны. Однако назвать нейросеть автором нельзя, поскольку цель авторского права — показать, у кого есть приоритет в использовании результатов творчества, а искусственный интеллект на своё творчество видов не имеет. В некоторых странах юристы обсуждают вариант наделить ИИ, а также роботов и прочие «умные» машины отдельными правами и обязанностями — определить их в законах как «техническое лицо». Но это пока лишь концепция, неизвестно, будут ли её развивать.
Можно не заморачиваться с правами и объявить, что всё сгенерированное нейросетями переходит в публичное достояние и им может пользоваться любой человек без ограничений. Однако создание алгоритма и его обучение отнимает у людей много сил, времени и даже денег — особо «массивные» алгоритмы требует мощных вычислительных ресурсов и тратят во время работы огромное количество электроэнергии. Отказать создателям нейросети в защите их интересов будет несправедливо.
 Твоё лицо, когда не можешь сочинить симфонию
Твоё лицо, когда не можешь сочинить симфонию
В законодательстве России есть понятие смежных прав — такие возникают у издателей, которые выпускают произведения, уже ставшие общественным достоянием, у артистов-исполнителей, у разработчиков баз данных. Некоторые юристы считают, что охранять творчество ИИ следует именно в таких понятиях. Другие же указывают на то, что смежные права вторичны по отношению к авторским и надо сначала определить, кого считать автором, а уже потом разрешать или не разрешать кому-либо постороннему пользоваться результатами его работы.
Авторами вполне можно было бы назвать тех, кто способствовал появлению произведения. Однако и тут есть несколько непонятных моментов. Во-первых, чьи права приоритетнее — разработчика или пользователя? Одни разработчики выкладывают уже полностью натренированные модели, которые не требуют от пользователя ровно никаких усилий. Другие публикуют лишь каркас, а обучать и натаскивать алгоритм для выполнения той или иной задачи должен сам пользователь. Можно было бы отдать приоритетное право тому, на чьей машине появилось произведение, однако этот вариант не предусматривает использования облачных технологий.
Готового комплексного решения пока нет ни у кого, и неизвестно, появится ли оно в ближайшие годы.
Автор — голограмма?
 Медицинская голограмма звездолёта «Вояджер» (актёр Роберт Пикардо)
Медицинская голограмма звездолёта «Вояджер» (актёр Роберт Пикардо)
В сериале «Звёздный путь: Вояджер» был такой персонаж, Доктор, — экстренная медицинская голограмма и, по сути, «сильный» ИИ, который исполнял обязанности главного медицинского офицера. На протяжении всего полёта «Вояджера» он изучал свои творческие возможности и к двадцатому эпизоду седьмого сезона дозрел до публикации собственного голографического романа. Увы, его опыт работы с издательской сферой двадцать четвёртого столетия оказался негативным. Издатель отказался по требованию Доктора отозвать роман для доработки, апеллируя к тому, что у голограммы нет прав распоряжаться собственным произведением. По законам Федерации авторские права могут принадлежать только человеку.
Последовало судебное разбирательство. Защитники Доктора требовали признать его равным человеку, однако судья с этим не согласился. Он не был уверен в том, что голограмма способна принимать собственные решения, в том числе творческие, а не просто действует в соответствии с программой, заложенной людьми. Но он расширил для Доктора юридическое понятие автора в той части, что касается прав на собственные произведения.
Казалось бы, фантастика двадцатилетней давности, но подобные вопросы скоро придётся решать и нам.
* * *
Творческие способности искусственного интеллекта только начинают формироваться. Его первые шаги могут кому-то показаться неловкими, смешными или незначительными, однако не стоит забывать, что каждый человек тоже много тренируется, чтобы достичь хотя бы минимального успеха в своей области искусства. Он работает над собой, шлифует навыки, пробует разные техники. Поэтому, прежде чем издевательски предлагать бездушной машине написать шедевр, только представьте, сколько пришлось бы учиться вам, чтобы сделать то же самое.
Ваша реакция?








Мы думаем Вам понравится
-
![Антирейтинг немецкого супероружия, или Вундерваффе, которое лопнуло]()
Антирейтинг немецкого супероружия, или Вундерваффе, которое лопнуло
-
![Первые советские проигрыватели компакт-дисков «Луч»: как в СССР придумали собственный CD-дисковод, и почему он не пошел в серию]()
Первые советские проигрыватели компакт-дисков «Луч»: как в СССР придумали собственный CD-дисковод, и почему он не пошел в серию
-
![Эволюция знакомых с детства предметов быта, которые значительно упрощают жизнь хозяек]()
Эволюция знакомых с детства предметов быта, которые значительно упрощают жизнь хозяек
-
![Телефон с бритвой, топливный бак в виде сидения и др: 7 изобретений, которые не так хороши, как думали их создатели]()
Телефон с бритвой, топливный бак в виде сидения и др: 7 изобретений, которые не так хороши, как думали их создатели
-
![Самые гениальные рисунки Леонардо да Винчи]()
Самые гениальные рисунки Леонардо да Винчи
-
![«Кремлёвская таблетка» в зад, расчёска для мыслей и другие медицинские чудо-гаджеты шарлатанов]()
«Кремлёвская таблетка» в зад, расчёска для мыслей и другие медицинские чудо-гаджеты шарлатанов















